최신버전Databricks-Certified-Data-Engineer-Associate완벽한시험공부자료시험덤프자료
Wiki Article
그리고 ExamPassdump Databricks-Certified-Data-Engineer-Associate 시험 문제집의 전체 버전을 클라우드 저장소에서 다운로드할 수 있습니다: https://drive.google.com/open?id=17nor-TIw0QyGiw1YHM_lX-X9gGYOCuxe
지금21세기 IT업계가 주목 받고 있는 시대에 그 경쟁 또한 상상할만하죠, 당연히 it업계 중Databricks Databricks-Certified-Data-Engineer-Associate인증시험도 아주 인기가 많은 시험입니다. 응시자는 매일매일 많아지고 있으며, 패스하는 분들은 관련it업계에서 많은 지식과 내공을 지닌 분들뿐입니다.
Databricks 인증 데이터 엔지니어 어소시에이트 자격증은 데이터 엔지니어링 분야에서 기술과 지식을 인증하고자 하는 전문가들에게 우수한 자격증입니다. 이 자격증은 전문가들의 경력을 증진시키고 수익 가능성을 높일 수 있어 데이터 엔지니어링 분야에 관심이 있는 모든 사람들에게 가치 있는 투자입니다.
Databricks-Certified-Data-Engineer-Associate 시험을 준비하기 위해서는 Databricks 및 여러 구성 요소에 대한 깊은 이해가 필요합니다. 후보자는 Spark SQL, Spark Streaming 및 Spark MLlib에 대한 경험이 있어야 하며, 데이터 모델링, 데이터 구조 및 알고리즘에 대한 견고한 이해도가 필요합니다. 또한 Hadoop, Kafka 및 AWS S3와 같은 일반적인 데이터 저장 및 처리 기술에 익숙해야 합니다.
>> Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 <<
Databricks-Certified-Data-Engineer-Associate유효한 시험 - Databricks-Certified-Data-Engineer-Associate최신 덤프데모 다운로드
Databricks인증 Databricks-Certified-Data-Engineer-Associate시험패스는 고객님의 IT업계종사자로서의 전환점이 될수 있습니다.자격증을 취득하여 승진 혹은 연봉협상 방면에서 자신만의 위치를 지키고 더욱 멋진 IT인사로 거듭날수 있도록 고고싱할수 있습니다. ExamPassdump의 Databricks인증 Databricks-Certified-Data-Engineer-Associate덤프는 시장에서 가장 최신버전으로서 시험패스를 보장해드립니다.
Databricks-Certified-Data-Engineer-Associate 시험은 Databricks 플랫폼 사용에 능숙함을 증명하고자 하는 개인들에게 탁월한 자격증입니다. 이 시험은 성공적인 데이터 엔지니어링을 위해 중요한 다양한 주제를 다룹니다. 이 시험을 통과한 후보자들은 복잡한 데이터 엔지니어링 과제를 다루기 위해 필요한 전문 지식을 가지고 있어, 고용주들에게 높은 가치를 부여받습니다.
최신 Databricks Certification Databricks-Certified-Data-Engineer-Associate 무료샘플문제 (Q18-Q23):
질문 # 18
Which of the following describes the relationship between Bronze tables and raw data?
- A. Bronze tables contain a less refined view of data than raw data.
- B. Bronze tables contain less data than raw data files.
- C. Bronze tables contain raw data with a schema applied.
- D. Bronze tables contain more truthful data than raw data.
- E. Bronze tables contain aggregates while raw data is unaggregated.
정답:C
설명:
Bronze tables are the first layer of a medallion architecture, which is a data design pattern used to organize data in a lakehouse. Bronze tables contain raw data ingested from various sources, such as RDBMS data, JSON files, IoT data, etc. The table structures in this layer correspond to the source system table structures
"as-is", along with any additional metadata columns that capture the load date/time, process ID, etc. The only transformation applied to the raw data in this layer is to apply a schema, which defines the column names and data types of the table. The schema can be inferred from the data source or specified explicitly. Applying a schema to the raw data enables the use of SQL and other structured query languages to access and analyze the data. Therefore, option E is the correct answer. References: What is a Medallion Architecture?, Raw Data Ingestion into Delta Lake Bronze tables using Azure Synapse Mapping Data Flow, Apache Spark + Delta Lake concepts, Delta Lake Architecture & Azure Databricks Workspace.
질문 # 19
Which of the following Structured Streaming queries is performing a hop from a Silver table to a Gold table?
- A.
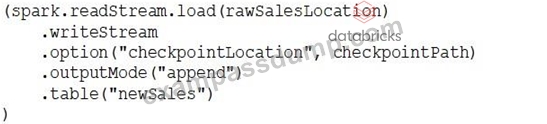
- B.
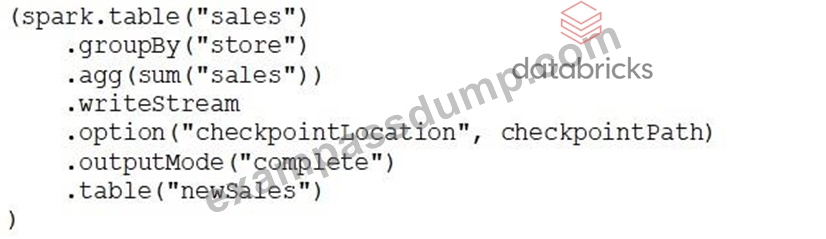
- C.

- D.

- E.

정답:B
설명:
The best practice is to use "Complete" as output mode instead of "append" when working with aggregated tables. Since gold layer is work final aggregated tables, the only option with output mode as complete is option E.
질문 # 20
A data engineer needs to read files from cloud object storage into a Spark DataFrame in Databricks. The files are stored in CSV format with headers and comma delimiters. Which Spark DataFrame reader option ensures that column names are correctly inferred from the first row?
- A. mode
- B. header
- C. inferSchema
- D. delimiter
정답:B
질문 # 21
A data engineer has three tables in a Delta Live Tables (DLT) pipeline. They have configured the pipeline to drop invalid records at each table. They notice that some data is being dropped due to quality concerns at some point in the DLT pipeline. They would like to determine at which table in their pipeline the data is being dropped.
Which of the following approaches can the data engineer take to identify the table that is dropping the records?
- A. They can set up separate expectations for each table when developing their DLT pipeline.
- B. They can navigate to the DLT pipeline page, click on the "Error" button, and review the present errors.
- C. They cannot determine which table is dropping the records.
- D. They can set up DLT to notify them via email when records are dropped.
- E. They can navigate to the DLT pipeline page, click on each table, and view the data quality statistics.
정답:B
질문 # 22
A data engineer has inherited a Databricks pipeline from a previous team. The pipeline is missing SLAs and costs more than the allotted budget. On analysis, it is noted that the cluster is not being fully utilized, and the dataset is getting skewed. How should the data engineer resolve this issue?
- A. Use coalesce() on the dataset to merge partitions and reduce skew.
- B. Increase the number of executors for the job.
- C. Repartition the dataset to have it be more optimally spread across all nodes.
- D. Increase the executor memory for the job.
정답:C
설명:
Repartitioning the dataset ensures data is evenly distributed across all nodes, reducing skew, improving cluster utilization, and helping control costs while meeting SLAs.
질문 # 23
......
Databricks-Certified-Data-Engineer-Associate유효한 시험: https://www.exampassdump.com/Databricks-Certified-Data-Engineer-Associate_valid-braindumps.html
- 높은 통과율 Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 시험대비자료 ???? 무료로 다운로드하려면▛ kr.fast2test.com ▟로 이동하여( Databricks-Certified-Data-Engineer-Associate )를 검색하십시오Databricks-Certified-Data-Engineer-Associate인증시험 덤프공부
- 시험패스에 유효한 최신버전 Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 시험대비자료 ???? ⇛ www.itdumpskr.com ⇚을(를) 열고➽ Databricks-Certified-Data-Engineer-Associate ????를 입력하고 무료 다운로드를 받으십시오Databricks-Certified-Data-Engineer-Associate인증시험대비 공부문제
- Databricks-Certified-Data-Engineer-Associate인증시험 덤프공부 ???? Databricks-Certified-Data-Engineer-Associate최신 인증시험 덤프데모 ⛰ Databricks-Certified-Data-Engineer-Associate적중율 높은 덤프 ???? ▶ www.exampassdump.com ◀은➽ Databricks-Certified-Data-Engineer-Associate ????무료 다운로드를 받을 수 있는 최고의 사이트입니다Databricks-Certified-Data-Engineer-Associate최신 업데이트 인증덤프자료
- 시험대비 Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 덤프 최신버전 ???? ⇛ www.itdumpskr.com ⇚에서➽ Databricks-Certified-Data-Engineer-Associate ????를 검색하고 무료로 다운로드하세요Databricks-Certified-Data-Engineer-Associate최신 업데이트 인증덤프자료
- 시험대비 Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 덤프 최신버전 ???? ➽ www.passtip.net ????웹사이트에서➤ Databricks-Certified-Data-Engineer-Associate ⮘를 열고 검색하여 무료 다운로드Databricks-Certified-Data-Engineer-Associate최고품질 인증시험 대비자료
- 시험패스에 유효한 최신버전 Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 시험대비자료 ???? ⇛ www.itdumpskr.com ⇚웹사이트를 열고➥ Databricks-Certified-Data-Engineer-Associate ????를 검색하여 무료 다운로드Databricks-Certified-Data-Engineer-Associate최신 인증시험 덤프데모
- 최신 Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 인증덤프 데모문제 다운 ???? [ www.exampassdump.com ]을(를) 열고▷ Databricks-Certified-Data-Engineer-Associate ◁를 검색하여 시험 자료를 무료로 다운로드하십시오Databricks-Certified-Data-Engineer-Associate퍼펙트 덤프 최신문제
- Databricks-Certified-Data-Engineer-Associate최신 업데이트 인증덤프자료 ???? Databricks-Certified-Data-Engineer-Associate인증덤프샘플 다운 ???? Databricks-Certified-Data-Engineer-Associate퍼펙트 인증덤프 ???? 검색만 하면《 www.itdumpskr.com 》에서✔ Databricks-Certified-Data-Engineer-Associate ️✔️무료 다운로드Databricks-Certified-Data-Engineer-Associate높은 통과율 인기덤프
- 최신 Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 인증시험공부 ???? 검색만 하면[ www.pass4test.net ]에서➠ Databricks-Certified-Data-Engineer-Associate ????무료 다운로드Databricks-Certified-Data-Engineer-Associate인기자격증 인증시험덤프
- 최신 Databricks-Certified-Data-Engineer-Associate완벽한 시험공부자료 인증덤프 데모문제 다운 ???? 무료로 쉽게 다운로드하려면{ www.itdumpskr.com }에서【 Databricks-Certified-Data-Engineer-Associate 】를 검색하세요Databricks-Certified-Data-Engineer-Associate덤프데모문제 다운
- Databricks-Certified-Data-Engineer-Associate최신 업데이트버전 인증덤프 ???? Databricks-Certified-Data-Engineer-Associate적중율 높은 덤프 ???? Databricks-Certified-Data-Engineer-Associate합격보장 가능 덤프공부 ???? 오픈 웹 사이트⇛ www.itdumpskr.com ⇚검색( Databricks-Certified-Data-Engineer-Associate )무료 다운로드Databricks-Certified-Data-Engineer-Associate인증덤프샘플 다운
- academia.clinicaevolve.ro, arunmajn826700.mappywiki.com, wearethelist.com, rebeccayksv492679.tusblogos.com, estelleamjz030688.hazeronwiki.com, orangebookmarks.com, listedirectory.com, sachintojo095146.fare-blog.com, lawsonuman238943.blogsvila.com, sarahmdash.com, Disposable vapes
그리고 ExamPassdump Databricks-Certified-Data-Engineer-Associate 시험 문제집의 전체 버전을 클라우드 저장소에서 다운로드할 수 있습니다: https://drive.google.com/open?id=17nor-TIw0QyGiw1YHM_lX-X9gGYOCuxe
Report this wiki page